AI Draft Review: A Lean Team's Operations Playbook
Most solo founders using AI writing tools end up in the same place: a Notion folder full of drafts, a vague sense that some of them are "pretty good," and no reliable way to tell which ones are actually ready to publish. The tool ran. The draft exists. Now what?
That gap, between "draft generated" and "confident to publish," is where content quality dies. Not from bad AI output. From no system for evaluating it.
This post is a vendor-neutral operations blueprint. It defines the three review roles every content workflow needs (even when one person plays all of them), a three-tier SLA model based on content risk, and a five-dimension checklist that turns a vague gut check into a repeatable publish decision.
Why "I'll just read it over" isn't a workflow
Reading a draft once and deciding it feels fine is not a review process. It's a coin flip with extra steps.
The failure mode is predictable. Without defined criteria for what "good" means, reviewers default to inconsistent spot-checks. They catch the things that happen to catch their eye and miss the things that don't. Redbricklabs.io notes that without defined confidence thresholds and routing rules, human reviewers drift toward unstructured audits rather than systematic ones. That drift compounds over time. Post 12 sounds different from post 3. A citation in post 7 is fabricated and nobody caught it.
The cost of that one fabricated citation is not symmetrical with the benefit of the posts around it. A single published claim that turns out to be wrong, a stat that traces back to a non-existent study, a quote attributed to someone who never said it, can undo months of credibility-building. The Authors Guild's AI best practices state it plainly: AI outputs must be verified because models "can generate plausible-sounding but incorrect information." That's not a knock on any specific tool. It's a structural property of how these systems work.
The fix isn't more careful reading. It's a decision protocol. Onelogicsoft.com's workflow guidance calls out that defining "approval roles, override rules, and escalation paths" before automating is what separates reliable processes from fragile ones. The same principle applies to content review. You need the protocol first. Then the reading becomes faster, not slower, because you know exactly what you're looking for.
The three roles (even if you're all of them)
Every content review, regardless of team size, needs three functional roles filled. They can all be the same person. But they can't happen at the same time.
- Research auditor: confirms every cited stat, URL, and claim is real and current. Clicks every link. Checks that quoted numbers match the source they're attributed to.
- Brand voice editor: checks tone, sentence rhythm, banned phrases, and whether the post sounds like the founder wrote it. Not whether it's grammatically correct. Whether it's recognizably yours.
- Publish gatekeeper: makes the final go/no-go call against SEO frontmatter, internal link targets, and CTA alignment. The final checkpoint before the post goes live.
The reason to separate these roles, even when you're a team of one, is cognitive. Redbricklabs.io's human-in-the-loop framework recommends separating review tasks by type to reduce cognitive load and catch errors that a single pass misses. When you're simultaneously checking citations and listening for brand voice drift, you do both worse. Sequential passes, each with a single job, catch more.
Onelogicsoft.com identifies "documented handoffs" and "defined inputs per role" as recommended practices that help improve review accuracy. In practice, for a solo founder, that means finishing the research audit completely, making a note of anything flagged, then switching contexts before starting the voice edit.
A well-structured AI draft changes what each role is actually doing. When the tool delivers an evidence packet alongside the draft, source URLs, pulled quotes, citation counts, an initial quality score, the research auditor starts from structured inputs instead of hunting through the prose for claims to verify. That's the difference between a discovery pass and a confirmation pass.
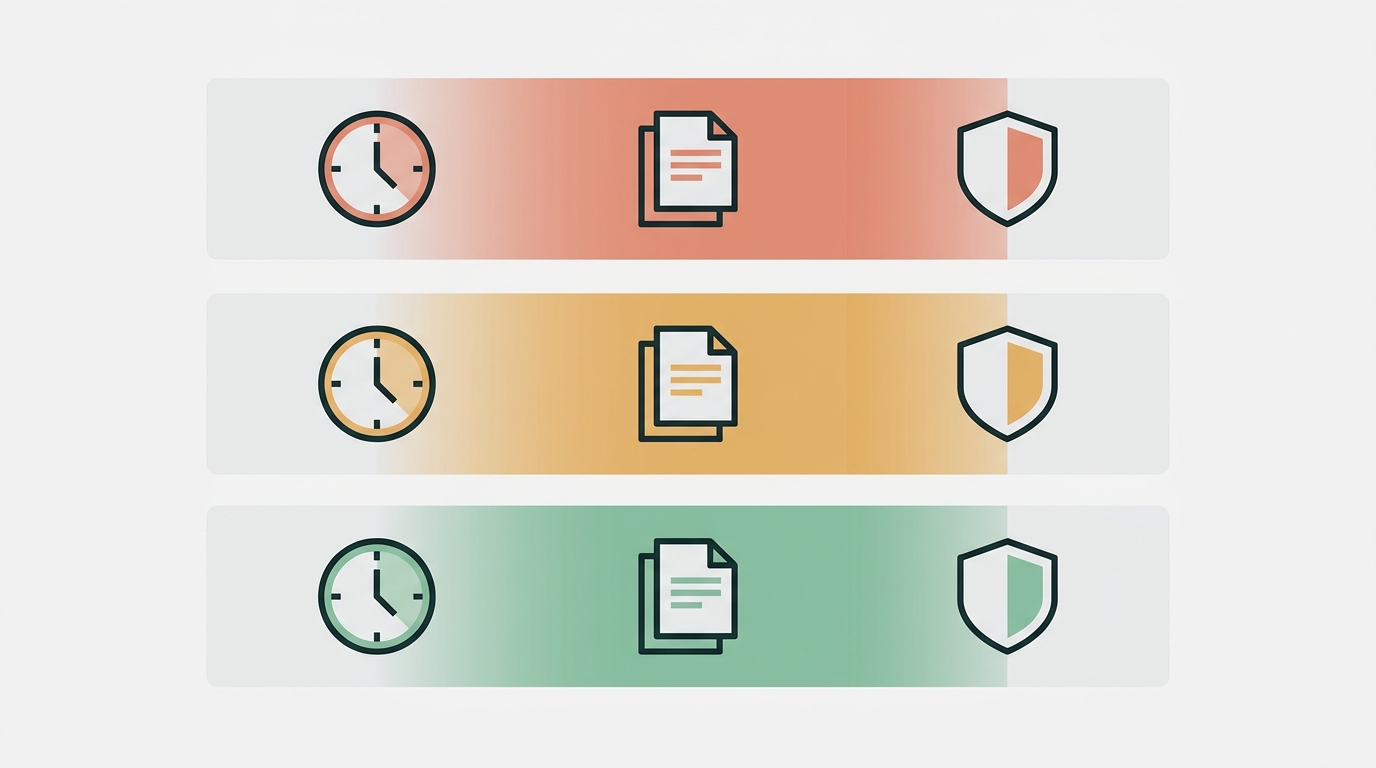
SLA tiers: match review depth to content risk
Not every post needs the same scrutiny. A 600-word how-to post on setting up a Stripe webhook doesn't carry the same risk as a comparison post naming a competitor's pricing, and neither does a thought leadership piece you're about to put $2,000 of ad spend behind.
A three-tier model routes each draft to the right depth of review without over-engineering the process.
Tier 1 (low risk, 30-minute SLA): Evergreen how-to posts. No proprietary claims. Citations are general knowledge or link to widely-known primary sources. The review is mostly a voice check and a quick link scan.
Tier 2 (medium risk, 2-hour SLA): Comparison posts. Posts citing specific stats or naming competitors. Posts making product claims. These get the full three-role treatment: research audit first, voice edit second, gatekeeper sign-off third.
Tier 3 (high risk, 24-hour SLA): Thought leadership with original assertions. Anything touching legal or compliance territory. Any post that will run as a paid ad. These get an extra verification pass and, where possible, a second reader before publish.
You can classify any draft into a tier in under 60 seconds using three questions:
- Does it name a competitor?
- Does it cite a specific number?
- Will it run as an ad?
If none of the above apply, it's Tier 1. One yes is usually Tier 2. Two or more is Tier 3. That's the whole triage. Redbricklabs.io's risk classification framework uses a similar three-question triage to route AI actions to the appropriate approval level.
Most solo founder content should land in Tier 1 or Tier 2. That means the full review workflow, done properly, is a suggested target of under two hours per post. Onelogicsoft.com notes that defining SLA benchmarks upfront lets teams measure SLA misses and identify exactly where the process is breaking down. That metric is more useful than "we publish three posts a week" because it tells you whether those posts are being reviewed well or just reviewed quickly.
The review checklist: five dimensions, one pass
A checklist works because it makes the standard explicit. You're not asking "does this feel right?" You're asking five specific questions with yes/no answers.
1. Factual accuracy. Every stat has a live URL. Every named claim is verifiable. No fabricated citations. Click every link in the draft during this pass.
2. Brand voice. No banned phrases. Sentence rhythm matches your established style anchors. First-person and second-person used correctly throughout.
3. SEO structure. Target keyword appears in the H1 and within the first 100 words. Meta description is under 160 characters. Internal links are present and pointing to the right targets.
4. Argument integrity. Claims follow from evidence. No logical gaps between a premise and its conclusion. No unsupported superlatives ("the best," "the only," "the fastest") without data behind them.
5. Reader action. The CTA is specific. The post ends with something the reader can do, not a summary of what they just read.
When an AI agent runs a structured quality audit before the draft reaches you, this checklist becomes a confirmation pass rather than a discovery pass. You're verifying that the dimensions check out, not hunting to see whether they've been considered at all. The Authors Guild's guidance frames this well: human review of AI content should focus on "verification and voice" rather than wholesale rewriting. That's only achievable when the AI has already done structured self-assessment and handed you the output.
The single highest-leverage item on the list is factual accuracy, specifically citation verification. It's the failure mode that's invisible to casual readers and catastrophic when caught. The Authors Guild explicitly warns that AI tools "can generate plausible-sounding but incorrect information" and that authors bear full responsibility for what they publish. That responsibility doesn't transfer to the tool. Every citation you publish is yours.

Building the review dashboard (without a project management tool)
You don't need software. You need a single source of truth for where every draft stands.
A simple four-column kanban structure handles it: Drafted / In Review / Approved / Scheduled. Every draft card carries five pieces of metadata:
- Tier classification (1, 2, or 3)
- Assigned reviewer role(s) and who's handling each
- SLA deadline based on tier
- Quality score from the AI audit
- Citation count
Onelogicsoft.com recommends maintaining an audit log of review decisions as a baseline for measuring process quality over time. In practice, that means recording not just whether a draft was approved, but which checklist items were flagged, what was fixed, and how long the review actually took versus the SLA.
Redbricklabs.io's implementation guidance adds that review dashboards should surface "confidence scores and risk flags" so reviewers can prioritize without reading every draft in full. If you're managing five drafts at once, you want to pull Tier 3 posts to the top of the queue before your Tier 1 evergreen pieces.
A shared Notion table or Airtable base handles this for teams of one to five. The tool doesn't matter. What matters is that the draft status, tier, and review outcome live in one place and not across three Slack threads and a sticky note.
If your AI writing tool outputs structured markdown with SEO frontmatter, inline citations, and a quality score already included, that output drops directly into the dashboard card without reformatting. That's the difference between a tool that generates text and a tool that generates reviewable drafts.
When to escalate, when to kill, when to ship
Every draft ends in one of three decisions. Knowing which one applies before you start the review makes the process faster.
Ship: The quality score meets your threshold. All five checklist dimensions pass. The SLA is met. Publish it.
Revise: One or two checklist items fail but the core argument is sound. Send the draft back with specific flags, not a general "needs work." "The stat in paragraph four doesn't match the linked source" is a useful flag. "The tone feels off" without specifics is not.
Kill: Factual accuracy fails on a core claim, or the post contradicts a previously published position. Document the kill reason in the audit log and re-generate with a corrected brief. Redbricklabs.io recommends defining explicit "escalation paths" and turnaround times so reviewers don't get stuck in revision loops.
The practical rule for "revise vs. kill": if fixing the post requires rewriting more than 40% of the draft, the brief was wrong, not the draft. Kill it, fix the brief, and re-generate. Revising 40% of a draft by hand usually costs more time than regenerating, and produces a less coherent result because you're stitching two writing sessions together.
The audit log entry for a killed post is worth writing carefully. Note what the brief said, what the draft produced, and what was wrong. That record is what prevents the same brief from producing the same unusable draft next month.
FAQ
How long does this whole workflow actually take per post?
For Tier 1 posts, under 30 minutes if you're working from a structured draft with an evidence packet already attached. Tier 2 posts with the full three-role review run 60 to 90 minutes in practice. Tier 3 posts with a 24-hour SLA build in buffer for a second reader and any fact-checking that requires reaching out to a source.
Do I really need to separate the three roles if I'm the only reviewer?
Yes, but not with calendar blocking. Finishing the research audit before switching to the voice edit is enough. The cognitive benefit comes from doing one type of attention-intensive task at a time, not from making the switch formal. Even a five-minute break between passes helps.
What's the right quality score threshold for publishing?
That depends on what your tool scores against. If you're using a five-dimension audit, a post that passes four of five dimensions is the author's recommended threshold for publishable with targeted fixes. A post failing factual accuracy or argument integrity, regardless of how well it scores on the other three, is not. Set your thresholds by dimension, not by overall average.
What if the AI draft is well-written but the citations trace back to weak sources?
That's a Tier 2 or Tier 3 flag depending on the claim. Replace weak sources with primary sources or remove the claim entirely. A qualitative sentence without a citation is more credible than a statistic linked to a content farm. The Authors Guild's guidance is clear: you're responsible for what you publish, regardless of where the initial draft came from.
How do I handle a draft where the core argument is good but the voice is completely wrong?
That's a revise decision, not a kill. Flag the specific phrases, rhythm patterns, or structural choices that break from your brand voice. If your AI tool has a brand voice input, this is also signal that the voice configuration needs updating. A post that nails citations and structure but sounds generic usually means the style anchor wasn't specific enough, not that the tool failed.
Sources
- Red Brick Labs: How to Build a Human Approval Layer for AI Workflows
- Onelogicsoft: AI Workflow Automation — How to Decide What Should Be Automated First
- Authors Guild: AI Best Practices for Authors
If you want to skip the part where you build this workflow from scratch, Ryterr generates the draft, the evidence packet, and the five-dimension quality score in a single run. You start at the confirmation pass, not the discovery pass. Try it at ryterr.com and ship your first reviewed post today.