First-Party Data Posts: Mine Your Product for Blog Topics
Open any competitor's blog in your niche. Then open yours. If the H2 structure looks familiar, that's not a coincidence. You both started with the same keyword tool, ran the same search volume filters, and ended up targeting the same 10 topics. The posts are slightly different in word count. The argument is identical.
There's a way out of that loop. Your product already generates data no one else can access. Usage telemetry, support ticket clusters, onboarding survey responses. That data is raw material for posts that can't be copied because they can't be researched from the outside. This post walks through how to identify the right sources, pull a real post angle from the numbers, pressure-test it before you publish, and turn one data source into a full editorial calendar.
Why Your Blog Sounds Like Everyone Else's
Most content teams start with a keyword tool and end with a topic list that looks almost identical to every competitor in the space. That's not a failure of effort. It's a structural problem. Keyword tools pull from the same search index. Everyone using the same tool, targeting the same audience, ends up in the same place.
Semrush's own keyword research guide acknowledges that first-party sources like sales calls and support tickets are valid inputs for topic discovery. That's true, and useful. But most teams stop there. They use the ticket language to find a keyword, then write a generic post around that keyword. The proprietary signal gets stripped out before the post is written.
The result: a post with no claim that requires your data to make. Any competitor can write the same piece tomorrow. They probably will.
There's also a trust problem. Readers who've spent time in a category can tell the difference between a post built on recycled industry stats and one built on real observation. The first one cites the same Gartner report everyone else cites. The second one says "we looked at our last 500 support tickets and here's what customers actually misunderstand about this." That second post is harder to dismiss.
The Three Data Sources Already Sitting in Your Product
You don't need a data team or a research budget. Three sources are already generating usable signal, and you probably check at least one of them weekly.
Usage telemetry. Feature adoption rates, drop-off points, workflow sequences. These show how customers actually use your product versus how you assumed they would during spec. If a significant share of users consistently skip a feature you built first, that's a post. The angle writes itself: "Why most teams skip [feature], and what they do instead." The data is the argument. No competitor can replicate it.
Support ticket themes. Recurring questions cluster around real confusion points. Those confusion points map directly to search intent because the person who emailed you also Googled the same question first. As Semrush notes, support tickets are a first-party keyword source. But there's more value in them than a keyword. The ticket text contains the exact language your customers use to describe the problem. That phrasing is more useful than a search volume number because it tells you not just what to write about, but how to frame it.
Onboarding and survey responses. Free-text fields in onboarding flows, NPS follow-ups, and cancellation surveys contain the "jobs to be done" framing customers use to describe their own problems in their own words. These are primary sources. No competitor has access to them. No amount of keyword research surfaces them.
Three sources. All available now. None require a third-party data purchase.
How to Extract a Post Angle From Raw Data
Raw data is not a post. A number sitting in your analytics dashboard does nothing until someone asks what it means and why a reader should care.
There are three distinct layers here, and conflating them produces weak posts.
A data point is a number: "42% of users who completed onboarding never published a post." A data point is a fact, nothing more.
An insight is what the number means: setup friction is killing activation. Users finish onboarding in a technical sense but never reach the outcome they signed up for.
A post angle is the argument a reader would care about: "Why most AI writing tools fail at the last step, and how we fixed it." That's a claim. It has a subject, a problem, and a resolution. A reader in your target audience would click it.
The test for whether an angle is differentiated: could a competitor write this post without your data? If yes, you haven't gone far enough. The angle needs to depend on your observations to be credible. If the argument could have been written by anyone with a keyboard and a keyword tool, the first-party data isn't doing any work.
Experian's first-party data activation piece makes a parallel point about data activation more broadly: first-party data earns value only when it's put to use. The same logic applies here. The usage data sitting in your dashboard is inert until you form a claim around it and publish it.
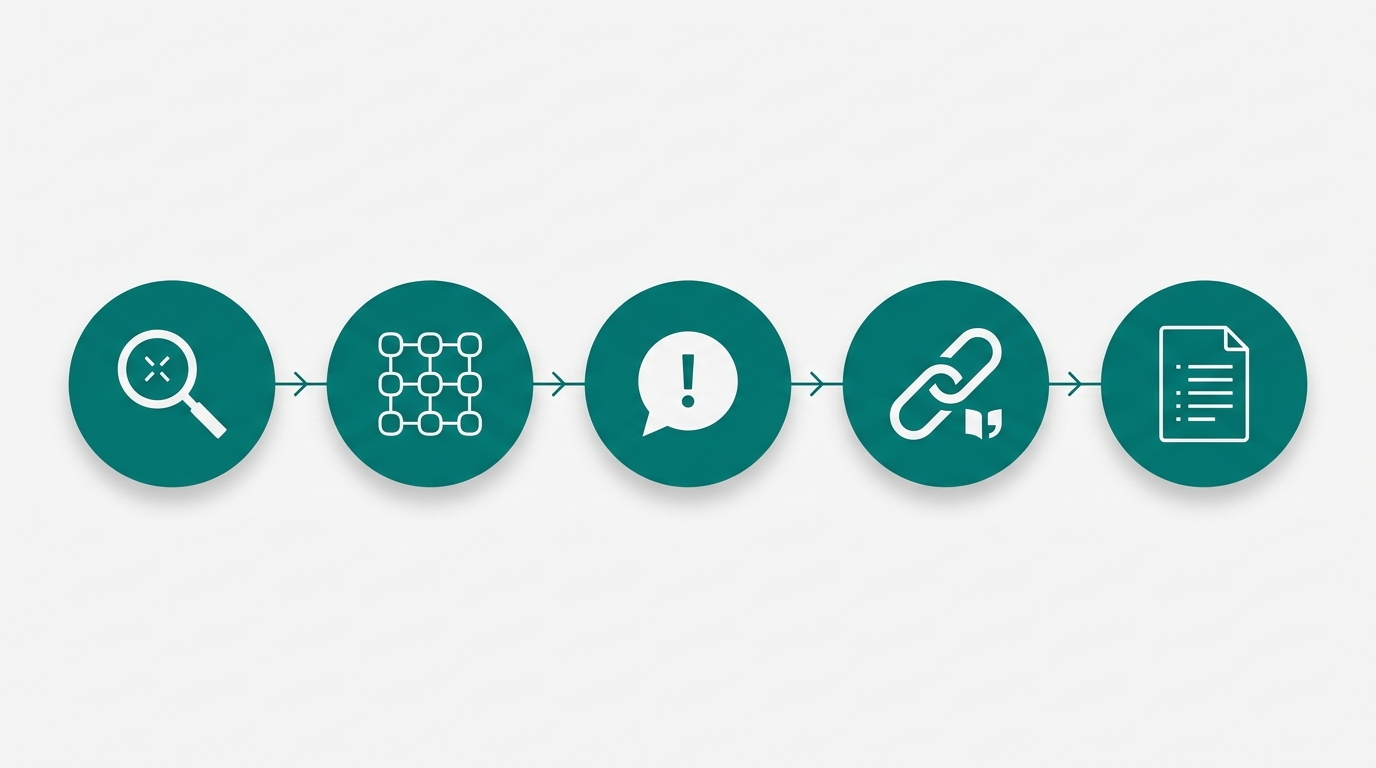
The Research-to-Outline Workflow (Repeatable)
This is the part most founders skip. They go straight from "I noticed something interesting in the data" to writing prose. That produces a meandering post with a buried argument. Do these five steps first.
Step 1: Identify one source. Pick usage data, support tickets, or survey responses. One per post. Mixing sources in a single post diffuses the argument and makes the post harder to pitch in a headline.
Step 2: Extract the pattern. Look for the outlier, the cluster, or the gap. Interesting posts come from behavior that surprises you. If the data confirms exactly what you expected, it's probably not a strong angle. The surprise is the signal.
Step 3: Form a falsifiable claim. Write one sentence that could be proven wrong. "Founders who publish weekly grow organic traffic faster" is testable. "Content is important for growth" is not. Vague claims produce vague posts because there's no argument to structure the writing around.
Step 4: Find external citations that support or contextualize the claim. Your first-party data is the unique angle. Published research adds credibility and gives the post SEO signal beyond your own brand. This is where live web research earns its keep.
Step 5: Build the outline before writing prose. Structure the argument first. A post built on a data insight needs a clear claim, supporting evidence, and a concrete takeaway, in that order. Writing before you have that structure produces a draft that wanders.
Each step takes 5-10 minutes. The five steps together take less time than writing a bad first paragraph and deleting it.
Fact-Checking Your Own Data Before You Publish
First-party data has one big advantage over recycled industry stats: you know exactly where it came from. Use that. It also has one risk: you can deceive yourself.
Sample size matters. If your usage data covers a 30-day window that happened to follow a major UI change, it doesn't represent typical behavior. Publish that number without context and you've made a claim your own data doesn't support.
Recency matters. A pattern from 18 months ago may have been real then and reversed since. Check the date range before you form a claim.
Selection bias matters. Support ticket themes reflect customers who had a problem and emailed you. They don't represent customers who had the same problem and quietly churned, or customers who figured it out without asking. A ticket-based post needs to acknowledge what the sample captures and what it doesn't.
Showing this work is a trust signal, not a liability. A post that states "we looked at 400 support tickets submitted between January and March 2025" is more credible than a post that says "many customers struggle with X." Specificity signals that someone actually looked at the data. Coursera's marketing trends analysis connects first-party data to the broader privacy and cookie-deprecation narrative, and the underlying point applies here: proprietary data is more valuable than pooled data precisely because it's specific and attributable.
There's one more risk if you're using AI tools to draft the post. If the tool invents citations to support your data-backed claims, you've undermined the one thing that made the post worth writing. A fabricated URL attached to a real data point poisons both. Fact-checking the external citations is as important as fact-checking your internal numbers.
Turning One Data Source Into a Content Calendar
A single data source, worked properly, doesn't produce one post. It produces a quarter's worth.
Take support ticket themes from one quarter. Each recurring theme is a separate confusion post. Each resolved confusion point is a tutorial. Each cancellation survey response that mentions a competitor is a comparison angle. That's three post types from one source, and each theme generates one post per type.
Semrush's keyword research framework points to first-party sources as keyword inputs. Go further: the ticket themes don't just suggest keywords. They suggest the entire editorial structure.
Three post categories that map directly to first-party data:
- Confusion posts: What customers consistently misunderstand about your product or category. Sourced from ticket themes and failed onboarding patterns.
- Behavior posts: What customers actually do with your product, especially when it diverges from intended use. Sourced from usage telemetry.
- Outcome posts: What customers achieve when they use the product the way it was designed. Sourced from NPS responses and success stories in survey free-text fields.
The compound effect matters too. Each published post generates new reader behavior data: time on page, scroll depth, comment questions, inbound emails. That behavior feeds the next round of angles. The calendar is self-replenishing if you build it around real observation instead of keyword volume.
FAQ
What if my product is too early to have meaningful usage data?
Early-stage products don't generate large samples, but they do generate signal. Five detailed support tickets are enough to notice a pattern. Ten onboarding survey responses can surface a consistent framing problem. Start with what you have and note the sample size explicitly in the post. "We looked at our first 30 customer onboarding conversations" is honest and specific enough to be credible.
How do I write about internal data without revealing anything sensitive?
You don't need to publish raw numbers or user-identifiable behavior. Patterns and percentages at an aggregate level reveal nothing proprietary about individual users. The claim "most users complete setup but never reach their first published output" doesn't expose anything sensitive. Frame the observation at the level of behavior, not identity.
Does a post built on first-party data still need external citations?
Yes. Your internal data supports the unique angle. External citations support any claim that extends beyond your product's scope, and they add SEO credibility. The two types of sourcing serve different jobs in the same post. A post with only internal data looks self-serving. A post with internal data plus external context looks researched.
What's the minimum viable version of this workflow for a founder publishing solo?
Pick one source. Write down the single most surprising pattern you've noticed in the last 90 days. Form one falsifiable claim from that pattern. Find two external sources that add context. Build a five-section outline. That's the minimum. The full workflow takes under an hour before you write a single word of prose.
Can this approach work for content that isn't a data post, like tutorials or opinion pieces?
Yes. The workflow applies to any post with a first-party angle. A tutorial built on "the three most common setup mistakes from our support inbox" is first-party data. An opinion piece that opens with "we changed our onboarding flow and here's what happened to activation" is first-party data. The format doesn't matter. The requirement is that the core claim requires access to your observations to make.
Sources
- Semrush Keyword Research Guide
- Experian: First-Party Data Activation 2026
- Coursera: Marketing Trends
Open your support inbox, your usage dashboard, or the last batch of NPS responses you received. Write down three patterns you notice. From those three, pick the one that surprised you most and write one sentence that could be proven wrong. That sentence is your post. Try it at ryterr.com.